-
STT를 이용해 음성을 텍스트로 변환해보자 🗣️iOS 2023. 12. 26. 18:57
안녕하세요. 그린입니다 🍏
이번 포스팅에서는 iOS의 STT를 이용하여 음성을 텍스트로 변환하는 학습을 해보겠습니다 🙋🏻
순서는 STT가 무엇인지 알아보고 이를 프로젝트에서 활용하여 직접 음성을 텍스트로 변환해보는 코드까지 구현해보겠습니다!
그럼 STT가 대체 뭔지 알아볼까요?
STT(Speech-to-Text)란?
STT는 Speech-to-Text의 약자이며, 음성을 텍스트로 변환하는 기술을 말합니다.
주로, 음성 인식이나 음성 변환이라고도 불리고 음성 데이터 자체를 컴퓨터가 이해할 수 있는 형태로 변환하는 과정을 포함해요!
흔히 STT말고 TTS(Text-to-Speech)도 많이 들어보셨을텐데요!
이름에서도 유추할 수 있듯이 서로 반대의 개념입니다.
TTS는 텍스트를 음성 오디오로 변환하는것이고 STT는 음성을 텍스트로 변환하는거죠.
그런데 둘 다 AI와 머신러닝 알고리즘을 사용하고 있고 그런 방향으로 계속 발전하고 있기에 뗄레야 뗄 수 없겠죠!?
애플의 iOS 앱 개발에서 음성을 텍스트로 변환하기 위해 STT라는 기술을 자체적으로 내장하여 Speech 프레임워크를 사용하여 쉽게 개발자가 구현할 수 있도록 도와줍니다.그래서 STT가 무엇인지 살펴보았으니 음성을 텍스트로 변환해보는 코드를 구현하기전에 애플에서 제공하는 Speech 프레임워크에 대해 한번 톺아보고 가볼께요 🚀
Speech 프레임워크 톺아보기 🤔
Speech 프레임워크는 애플에서 기본적으로 제공하는 프레임워크로 라이브 혹은 사전 녹음된 오디오에서 음성 인식을 수행하고 텍스트 변환, 대체 해석 및 결과에 대한 신뢰 레벨을 수신할 수 있습니다.
즉, Speech 프레임워크를 사용해 녹음된 오디오 혹은 라이브 오디오에서 음성 단어를 인식해요.
키보드의 받아쓰기 지원은 음성 인식을 사용해 오디오 콘텐츠를 텍스트로 변환해줍니다.
우리도 흔히 음성으로 문자를 보내거나 할때 많이 사용하죠!?
여러 언어로 음성 인식을 수행할 수 있지만 각 개체는 단일 언어로 작동해요.
온디바이스 음성 인식은 일부 언어에 사용할 수 있지만 프레임워크는 음성 인식을 위해 애플 서버를 사용하게 됩니다.
그렇기에 해당 Speech를 이용하여 음성 인식을 수행하려면 꼭 항상 네트워크 연결이 되어야됩니다 🙋🏻
Speech 프레임워크에서 실제 바로 구현 코드에서 살펴볼 사용될 클래스들을 몇가지 짚어보겠습니다.
SFSpeechRecognizer
음성 인식 서비스의 가용성을 확인하고 음성 인식 프로세스를 시작하는데 사용하는 개체입니다.
class SFSpeechRecognizer : NSObject
클래스이며, 해당 개체로 핵심적인 음성 인식을 수행합니다.
사용을 위해서 음성 인식 권한을 요청하고 해당 객체를 생성합니다.
(음성 인식 권한 요청은 실제 구현해보는 파트에서 다룰 예정입니다!)
그리고 가용성을 확인하고 오디오 콘텐츠를 준비해 SFSpeechRecognitionRequest 개체를 만들어 음성 인식 시작을 위한 메서드를 호출합니다.
해당 메서드는 recognitionTask 메서드입니다.
일단 여기서는 해당 개체가 실제적인 음성 인식 기능을 해주는 역할을 한다~ 정도 알고 어떻게 사용되는지 어떤 메서드들이 이용되는지는 아래 실습 코드에서 설명하겠습니다 🙋🏻
SFSpeechAudioBufferRecognitionRequest
실제 디바이스 마이크의 오디오와 같이 캡처된 오디오 콘텐츠에서 음성을 인식하기 위한 요청을 하는 개체입니다.
class SFSpeechAudioBufferRecognitionRequest : SFSpeechRecognitionRequest
해당 개체를 사용해 오디오 음성 인식을 수행해요!
SFSpeechRecognitionTask
음성 인식 진행 상황을 모니터링하기 위한 작업 개체입니다.
class SFSpeechRecognitionTask : NSObject
개체를 사용하여 음성 인식 작업의 상태를 확인하거나, 중지, 취소 혹은 작업 종료 신호를 보낼 수 있습니다.
해당 개체는 직접 생성하지 않고 SFSpeechRecognizer 개체에서 recognitionTask(with:resultHandler:) 혹은 recognitionTask(with:delegate:)를 호출한 후 이러한 개체 중 하나를 받아 사용합니다.
자 이렇게 Speech 프레임워크에 대해 간단히 톺아봤으니 실제 음성을 텍스트로 변환해보는 코드를 구성해볼까요?
STT를 이용해 음성을 텍스트로 변환해보기 😃
이번 프로젝트에선 SwiftUI를 사용합니다.
또한, 애플에서 제공하는 STT 개발 튜토리얼을 참고하여 해당 구현들을 제 입맛대로 간소화 시켜 만들어본것으로 애플 공식 튜토리얼을 보시는것도 정말 많은 도움이 됩니다 🙋🏻Transcribing speech to text | Apple Developer Documentation
In this tutorial, you’ll add a feature to Scrumdinger that captures and logs meeting transcripts. You’ll request access to device hardware like the microphone and integrate the Speech framework to transcribe live audio to text.
developer.apple.com
1️⃣ 장치 하드웨어에 대한 승인 요청하기
오디오 녹음 및 음성 인식을 위해서 장치 마이크에 대한 액세스가 필요해요!
그렇기에 프로젝트에서 사용자에게 이 권한에 대해 액세스 할 수 있도록 요청하고 받아와야합니다 😃
Asking Permission to Use Speech Recognition | Apple Developer Documentation
Ask the user’s permission to perform speech recognition using Apple’s servers.
developer.apple.com
해당 사용 튜토리얼을 보면서 자세히 따라하셔도 되지만, 아래와 같이 추가할 수도 있습니다.
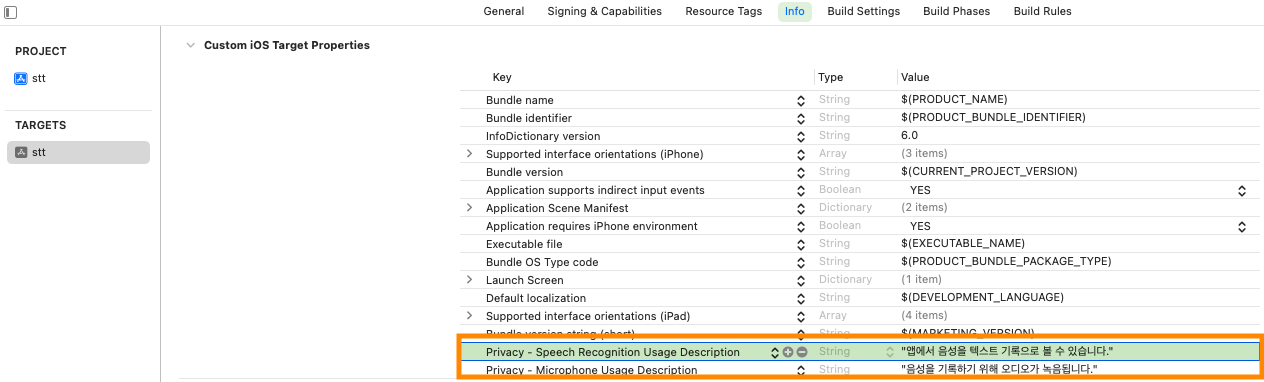
앱 타겟에서 Info 메뉴에 두가지를 추가해줍니다.
"Privacy - Speech Recognition Usage Description"
"Privacy - Microphone Usage Description"
준비는 끝났습니다!
코드 구현 가볼까요?
2️⃣ SpeechRecognizer 만들기
커스텀하게 저만의 SpeechRecognizer 객체를 만들어보겠습니다.
핵심 기능만 담은것으로, 여러분들은 더 많은 기능들을 담아 매니저 객체를 만들어도 좋을것 같습니다!
우선 껍데기를 보고 전체적은 그림을 설명해보고 각 메서드 별 하나씩 순차 접근해보겠습니다.
import Speech class SpeechRecognizer: NSObject, ObservableObject, SFSpeechRecognizerDelegate { private let speechRecognizer = SFSpeechRecognizer(locale: Locale(identifier: "ko-KR"))! private var recognitionRequest: SFSpeechAudioBufferRecognitionRequest? private var recognitionTask: SFSpeechRecognitionTask? private let audioEngine = AVAudioEngine() @Published var transcript = "" private var isTranscribing = false override init() { super.init() self.speechRecognizer.delegate = self } func startTranscribing() { // 음성인식 시작! } func stopTranscribing() { // 음성인식 종료! } private func cleanup() { // 설정 초기화! } }
껍데기는 이렇습니다.
SpeechRecognizer 클래스는 우선, ObservableObject를 따라 변화를 뷰에서 감지하고 반영할 수 있도록 해줍니다.
또한 SFSpeechRecognizerDelegate 프로토콜을 채택하여 SFSpeechRecognizer 인스턴스와 상호 작용하는 과정에서 발생할 수 있는 다양한 이벤트에 대응하도록 해줍니다.
예시로, 음성 인식 작업의 결과를 수신하고 인식 과정 중 변화나 오류에 대해 처리할 수 있죠.
그리고 이제 프로퍼티를 하나씩 어떤 용도로 사용할지 살펴볼까요?
speechRecognizer
SFSpeechRecognizer 인스턴스로 음성 인식 기능을 처리하고 결과를 반환하는데 사용합니다.
여기서는 한국어로 음성 인식 기능을 제공하도록 지역을 특정하여 넣어줍니다.
recognitionRequest
SFSpeechAudioBufferRecognitionRequest 인스턴스로 실시간 혹은 녹음된 오디오 데이터를 음성 인식 서비스에 전달하기 위한 요청 객체입니다.
이 요청을 이용해 오디오 데이터를 음성 인식기에 제공하고 음성 인식을 시작하죠!
recognitionTask
SFSpeechRecognitionTask 인스턴스로 음성 인식의 상태를 관리하고 결과를 받는 작업을 합니다.
음성 인식 요청의 진행 상태를 추적하고 필요한 경우에는 작업을 취소 및 중단도 할 수 있죠.
audioEngine
AVAudioEngine 인스턴스로 오디오 입력 및 출력을 관리합니다.
즉, 오디오 녹음을 시작하고 오디오 입력을 실시간으로 처리해 recognitionRequest에 오디오 데이터를 제공하는데 사용합니다.
transcript
텍스트로 변환된 음성 String 변수로 @Published 속성을 가지고 있어 추후 SwiftUI에서의 뷰가 감지하고 업데이트하기 위함입니다.
isTranscribing
현재 음성 인식이 진행중인지 여부를 파악하기 위한 변수로 추후 음성 인식을 시작하는 startTranscribing 메서드의 중복 실행을 방지합니다.
그리고 이니셜라이저에서 speechRecognizer의 딜리게이트를 자기 자신 self로 지정하여 음성 인식기의 딜리게이트 메서드들을 현재 클레스에서 처리할 수 있도록 구성해줍니다 😊
그리고 실제 구현을 해볼 세가지 메서드가 있어요!
음성 인식을 시작하고 종료할 메서드 그리고 설정을 초기화해주는 메서드 이렇게 구성되었습니다.
이제 이 세가지 메서드를 하나씩 구현해보면서 설명해보겠습니다 😃
startTranscribing()
일단 구현을 볼까요?
각 구현된 코드 부분에 주석을 달아서 간단히 설명을 해보면서 자세하게 설명이 필요한 부분은 텍스트로 아래에서 다루겠습니다!
func startTranscribing() { // 기존 음성 인식중인지 판단 guard !isTranscribing else { return } // 음성 인식 시작 판별 프로퍼티 상태 변경 isTranscribing = true // 오디오 엔진이 실행 중이면 중지하고 모든 tap을 제거 if audioEngine.isRunning { audioEngine.stop() audioEngine.inputNode.removeTap(onBus: 0) } // 기존 실행된 음성 인식 작업인, recognitionTask가 있다면 해당 작업 취소 recognitionTask?.cancel() recognitionTask = nil // 오디오 세션 설정 및 활성화 let audioSession = AVAudioSession.sharedInstance() do { try audioSession.setCategory(.record, mode: .measurement, options: .duckOthers) try audioSession.setActive(true, options: .notifyOthersOnDeactivation) } catch { print("오디오 세션 설정 실패: \(error)") isTranscribing = false return } // 음성 인식 요청 생성 recognitionRequest = SFSpeechAudioBufferRecognitionRequest() guard let recognitionRequest = recognitionRequest else { // 설정 중 오류 시 음성 인식 상태 변경 isTranscribing = false return } // 부분적 결과 보고 설정 recognitionRequest.shouldReportPartialResults = true // 음성 인식 작업 설정 recognitionTask = speechRecognizer.recognitionTask(with: recognitionRequest) { [weak self] result, error in guard let strongSelf = self else { return } var isFinal = false if let result = result { DispatchQueue.main.async { strongSelf.transcript = result.bestTranscription.formattedString } isFinal = result.isFinal } if error != nil || isFinal { // 초기화 strongSelf.cleanup() } } // 오디오 엔진에 tap을 추가 let recordingFormat = audioEngine.inputNode.outputFormat(forBus: 0) audioEngine.inputNode.installTap(onBus: 0, bufferSize: 1024, format: recordingFormat) { buffer, _ in recognitionRequest.append(buffer) } // 오디오 엔진 시작 do { try audioEngine.start() } catch { print("오디오 엔진 시작 실패: \(error)") cleanup() } }
조금 디테일하게 설명해볼 부분을 보겠습니다.
우선 오디오 엔진에서 node와 tap이 낯선데요.
inputNode를 통해 오디오 입력을 나타내고 tap을 설치하여 실시간으로 오디오 데이터를 받을 수 있도록 합니다.
여기서 onBus는 오디오 노드 내의 특정 버스에 tap을 설치해요.
여기서 0은 오디오 채널을 나타내고 0번 버스는 단일 입력 노드를 위함입니다.
bufferSize는 콜백에서 캡처할 오디오 데이터의 버퍼 크기를 설정하는것입니다.
이 값에 따라서 콜백의 호출 빈도와 오디오 데이터 양이 결정됩니다.
format은 캡처할 오디오 데이터의 포맷을 설정해요.
샘플링 레이트, 채널 수 등 오디오 데이터의 형식을 정의하죠.
block은 실제 오디오 데이터를 받아 처리하는 클로저입니다.
정의된 버퍼 크기만큼의 오디오 데이터를 주기적으로 받게되고 이 데이터를 사용해 추가 작업을 수행합니다.
즉, 음성 인식 요청에 오디오 버퍼를 추가하는데 사용합니다.
inputNode는 AVAudioEngine 클래스의 프로퍼티로 오디오 엔진의 오디오 입력 노드를 나타냅니다.
즉, 오디오 데이터의 입력, 처리, 출력 등을 담당해줍니다.
결국 SFSpeechAudioBufferRecognitionRequest 객체에 오디오 버퍼를 추가해 음성을 실시간으로 음성 인식 서비스로 전송하고 텍스트로 변환할 수 있게 활용됩니다.
다음으로 실제 음성 인식을 설정하고 음성 데이터를 텍스트로 변환하는 부분을 살펴보죠.
// 음성 인식 요청 생성 recognitionRequest = SFSpeechAudioBufferRecognitionRequest() guard let recognitionRequest = recognitionRequest else { // 설정 중 오류 시 음성 인식 상태 변경 isTranscribing = false return } // 부분적 결과 보고 설정 recognitionRequest.shouldReportPartialResults = true // 음성 인식 작업 설정 recognitionTask = speechRecognizer.recognitionTask(with: recognitionRequest) { [weak self] result, error in guard let strongSelf = self else { return } var isFinal = false if let result = result { DispatchQueue.main.async { strongSelf.transcript = result.bestTranscription.formattedString } isFinal = result.isFinal } if error != nil || isFinal { // 초기화 strongSelf.cleanup() } }
이 부분인데요.
먼저 recognitionRequest 음성 인식 요청 인스턴스를 생성합니다.
이 객체는 이제 오디오 데이터를 애플의 음성 인식 서버로 전송하는데 사용됩니다.
그리고 아래 guard let 구문을 통해 요청 인스턴스가 유효한지 검사합니다.
사실 없어도 되지만 조금 더 안정성을 위해 구현합니다.
그리고 부분적 결과 보고 생성 코드는 음성 인식 과정에서 부분 결과도 반환되도록 설정합니다.
이 코드를 통해 음성이 들어오는 동안 중간 인식 결과를 지속적으로 받아볼 수 있도록 해줍니다.
이제 음성 인식 작업 설정하는 코드를 살펴보면 recognitionTask(with: resultHandler:) 메서드를 호출해 음성 인식 작업을 시작해요.
이 작업은 비동기적으로 수행되며 결과와 오류는 클로저를 통해 처리됩니다.
if let 코드 부분에서는 실제 결과 처리 클로저로 음성 인식 결과가 있을 경우 변환된 텍스트에 값을 넣기 위해 가장 정확한 변환 텍스트의 값을 저장하는 코드입니다.
이 작업은 뷰에 반영되어야 하기에 메인 스레드에서 수행되도록 해줍니다.
마지막으로 인식이 완료되었다면 cleanup 메서드를 호출하여 초기화를 시켜줍니다.
이제 다음 stopTranscribing 메서드를 구현해볼께요.
stopTranscribing()
func stopTranscribing() { recognitionTask?.cancel() cleanup() }
음성 인식을 종료하기 위해 task를 취소시켜주고 초기화를 시켜줍니다.
마지막으로 초기화인 cleanup 메서드를 구현해볼까요?
cleanup()
private func cleanup() { if audioEngine.isRunning { audioEngine.stop() audioEngine.inputNode.removeTap(onBus: 0) } recognitionRequest?.endAudio() recognitionRequest = nil recognitionTask = nil isTranscribing = false // 인식 중 상태 해제 }
초기화를 위해 오디오 엔진이 실행중이면 멈추고 탭을 제거해줍니다.
그리고 오디오를 종료하고 request와 task를 nil로 해제시켜주고 인식중인 상태를 해제하여 코드를 구현할 수 있습니다.
이렇게 코드들을 구성할 수 있어요!
다음으로 이 객체를 사용할 뷰를 간단히 만들어 음성을 텍스트로 화면에 표현해볼까요?
3️⃣ 뷰 구현하기
import SwiftUI struct ContentView: View { @StateObject private var speechRecognizer = SpeechRecognizer() var body: some View { VStack { Text("Speech To Text") .font(.title) .padding() TextEditor(text: $speechRecognizer.transcript) HStack { Button(action: { speechRecognizer.startTranscribing() }) { Text("Start") .padding() .background(Color.blue) .foregroundColor(.white) .cornerRadius(8) } Button(action: { speechRecognizer.stopTranscribing() }) { Text("Stop") .padding() .background(Color.red) .foregroundColor(.white) .cornerRadius(8) } } .padding() } .padding() } }
간단합니다.
해당 SpeechRecognizer 인스턴스를 생성합니다.
그리고 적절히 뷰를 구성해줘요.
여기서는 Start 버튼을 클릭하면 음성 인식을 시작하고 Stop 버튼으로 음성 인식을 종료합니다.
그리고 음성 인식을 통해 텍스트로 변환된 문자열이 텍스트에디터에 쓰여지게 됩니다.
그럼 한번 동작을 볼까요?
동작해보기 📱

자 음성을 정상적으로 인식하여 변환된 텍스트가 나오는것을 확인할 수 있습니다!
어떤가요? 간단하죠? ㅎㅎ
마무리
이렇게 STT를 맛보면서 구현해봤습니다.
물론 더 다양한 구현을 해볼 수 있으니 니즈가 있으시면 공식 문서와 튜토리얼을 활용해보는걸 추천드립니다!
해당 프로젝트 예시 코드는 아래 제 깃헙 레포에 있으니 편하게 보고 사용하셔도 됩니다 😃
https://github.com/GREENOVER/playground/tree/main/practiceSTT
레퍼런스
Speech | Apple Developer Documentation
Perform speech recognition on live or prerecorded audio, and receive transcriptions, alternative interpretations, and confidence levels of the results.
developer.apple.com
Transcribing speech to text | Apple Developer Documentation
In this tutorial, you’ll add a feature to Scrumdinger that captures and logs meeting transcripts. You’ll request access to device hardware like the microphone and integrate the Speech framework to transcribe live audio to text.
developer.apple.com
'iOS' 카테고리의 다른 글
VoiceOver를 통한 이벤트 전송 (65) 2024.01.04 Get started with privacy manifests (feat. WWDC 2023) (84) 2023.12.28 UITest에서 accessibilityIdentifier 활용하기 (78) 2023.12.18 앱 지원 언어 추가 및 기본 언어 변경 (feat. Tuist) (68) 2023.12.14 Core Data 파헤치기 🔍 (55) 2023.12.07